
Initially, the main focus of this post was going to be quick and about using the latest version of SSMS (SQL Server Management Studio) to check out execution plans for Azure SQL Data warehouse (DW). I got a little side tracked by a certain operation called – SHUFFLE, because, I like the name.
With the latest SSMS version being 17.6 you have the ability to see the estimated execution plan (black box below). This is new and the other older way of getting plan information was via the EXPLAIN command.
For the purposes of this post the TSQL shown is elementary (don’t be surprised by that), the point is really about SHUFFLE. So, I select the estimated plan for the following code.
SELECT SOD.[SalesOrderID],SOD.[ProductID], SOH.[TotalDue] FROM [SalesLT].[SalesOrderDetail] SOD JOIN [SalesLT].[SalesOrderHeader] SOH ON SOH.[SalesOrderID] = SOD.[SalesOrderID] WHERE SOH.[TotalDue] > 1000

Shuffle me once, why not shuffle me twice. If you REALLY want to see the EXPLAIN command output, then it looks like this snippet below.

The DSQL operation clearly states SHUFFLE_MOVE. Why am I getting this? What does it mean?
To get your query results data movement might occur between compute nodes especially if your queries have joins and aggregations on distributed tables. In my case the salesorderdetail and salesorderheader tables.
There are two type of distributions:
- Hash Distributed – As you would expect, the idea of using a hashing values to distribute the data.
- Round Robin – Distribution of data evenly but randomly.
(There are also replicated tables which you can read about here: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/design-guidance-for-replicated-tables)
If you look at the structure for one my tables, it shows round robin distribution type.
CREATE TABLE [SalesLT].[SalesOrderHeader] ( [SalesOrderID] [int] NULL, [RevisionNumber] [tinyint] NULL, [OrderDate] [datetime] NULL, [DueDate] [datetime] NULL, [ShipDate] [datetime] NULL, [Status] [tinyint] NULL, [OnlineOrderFlag] [bit] NULL, [SalesOrderNumber] [nvarchar](25) NULL, [PurchaseOrderNumber] [nvarchar](25) NULL, [AccountNumber] [nvarchar](15) NULL, [CustomerID] [int] NULL, [ShipToAddressID] [int] NULL, [BillToAddressID] [int] NULL, [ShipMethod] [nvarchar](50) NULL, [CreditCardApprovalCode] [varchar](15) NULL, [SubTotal] [money] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [TotalDue] [money] NULL, [rowguid] [uniqueidentifier] NULL, [ModifiedDate] [datetime] NULL ) WITH ( DISTRIBUTION = ROUND_ROBIN, CLUSTERED INDEX ( [SalesOrderID] ASC ) )
Each join to a round-robin distributed table is a data movement operation. When you create tables in SQL DW this is a key topic, what sort of distribution type do you use and when you have decided that then what distribution column should you use? The answers to these questions won’t be answered here (I suggest reading this: https://blogs.msdn.microsoft.com/sqlcat/2015/08/11/choosing-hash-distributed-table-vs-round-robin-distributed-table-in-azure-sql-dw-service/) but I wanted to show you what happens if you ran the original query against a distributed table that uses hash. What do you think will happen? Well it depends on the column.
I create the following:
CREATE TABLE [SalesLT].[SalesOrderHeader3] ( [SalesOrderID] [int] NULL, [RevisionNumber] [tinyint] NULL, [OrderDate] [datetime] NULL, [DueDate] [datetime] NULL, [ShipDate] [datetime] NULL, [Status] [tinyint] NULL, [OnlineOrderFlag] [bit] NULL, [SalesOrderNumber] [nvarchar](25) NULL, [PurchaseOrderNumber] [nvarchar](25) NULL, [AccountNumber] [nvarchar](15) NULL, [CustomerID] [int] NULL, [ShipToAddressID] [int] NULL, [BillToAddressID] [int] NULL, [ShipMethod] [nvarchar](50) NULL, [CreditCardApprovalCode] [varchar](15) NULL, [SubTotal] [money] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [TotalDue] [money] NULL, [rowguid] [uniqueidentifier] NULL, [ModifiedDate] [datetime] NULL ) WITH ( DISTRIBUTION = HASH ( [CustomerID] ), CLUSTERED COLUMNSTORE INDEX ) GO CREATE TABLE [SalesLT].[SalesOrderDetail3] ( [SalesOrderID] [int] NULL, [SalesOrderDetailID] [int] NULL, [OrderQty] [smallint] NULL, [ProductID] [int] NULL, [UnitPrice] [money] NULL, [UnitPriceDiscount] [money] NULL, [LineTotal] [decimal](38, 6) NULL, [rowguid] [uniqueidentifier] NULL, [ModifiedDate] [datetime] NULL ) WITH ( DISTRIBUTION = HASH ( [ProductID] ), CLUSTERED COLUMNSTORE INDEX ) GO
I move data into the tables and re-run the query.
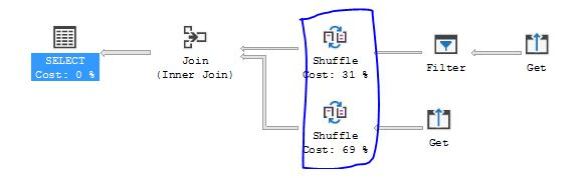
Still shuffling – why? For my case I am suffering from what is known as an incompatible join. This is when a query joins between two or more tables that are not distributed on the same column. Look at the tables above, my distributing columns are ProductID and CustomerID.
So I am motivated to remove the shuffle (whether that is right or wrong is another debate). I create these tables using the SalesOrderID as the hash distribution column.
CREATE TABLE [SalesLT].[SalesOrderDetailNew] ( [SalesOrderID] [int] NULL, [SalesOrderDetailID] [int] NULL, [OrderQty] [smallint] NULL, [ProductID] [int] NULL, [UnitPrice] [money] NULL, [UnitPriceDiscount] [money] NULL, [LineTotal] [decimal](38, 6) NULL, [rowguid] [uniqueidentifier] NULL, [ModifiedDate] [datetime] NULL ) WITH ( DISTRIBUTION = HASH ( [SalesOrderID] ), CLUSTERED COLUMNSTORE INDEX ) GO CREATE TABLE [SalesLT].[SalesOrderHeaderNew] ( [SalesOrderID] [int] NULL, [RevisionNumber] [tinyint] NULL, [OrderDate] [datetime] NULL, [DueDate] [datetime] NULL, [ShipDate] [datetime] NULL, [Status] [tinyint] NULL, [OnlineOrderFlag] [bit] NULL, [SalesOrderNumber] [nvarchar](25) NULL, [PurchaseOrderNumber] [nvarchar](25) NULL, [AccountNumber] [nvarchar](15) NULL, [CustomerID] [int] NULL, [ShipToAddressID] [int] NULL, [BillToAddressID] [int] NULL, [ShipMethod] [nvarchar](50) NULL, [CreditCardApprovalCode] [varchar](15) NULL, [SubTotal] [money] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [TotalDue] [money] NULL, [rowguid] [uniqueidentifier] NULL, [ModifiedDate] [datetime] NULL ) WITH ( DISTRIBUTION = HASH ( [SalesOrderID] ), CLUSTERED COLUMNSTORE INDEX ) GO
I run the query estimated plan.
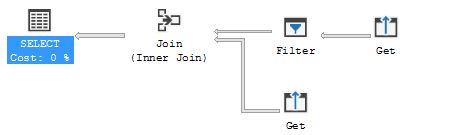
No more shuffle. Let me just say, I am not saying you should always be trying to remove shuffle (its inevitable in some cases), this post is a more curiosity fulfilling post as to the behaviours of shuffle and how table designs can change/affect this behaviour, yes it is generally an expensive operation you most likely do not want to see it especially against BIG tables because there is definite overhead (from what I saw anyways). Look at the comparing explain plans, it says a lot – just a note, the same number of rows exists between all tables just to make this experiment fair.
This is the shuffle, you can see it has a cost, number of operations is 9 and many temp tables created.
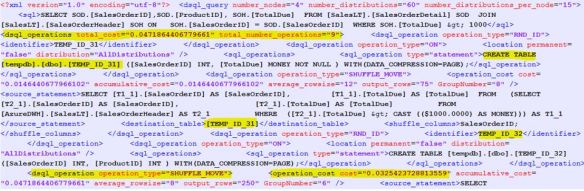
Further proof of this?
SELECT TOP 10 * FROM sys.dm_pdw_exec_requests ORDER BY total_elapsed_time DESC;
I then pass the relevant request ID into the below query.
SELECT * FROM sys.dm_pdw_request_steps WHERE request_id = 'QID4283' ORDER BY step_index;
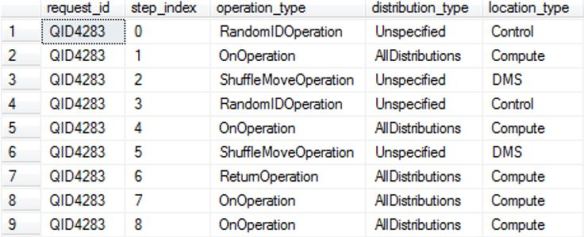
Versus – No shuffle (my compatible joins) you can see the dsql operation information does not mention shuffle.
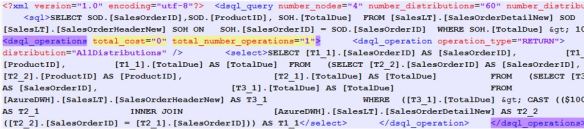
Again I check sys.dm_pdw_request_steps.
SELECT * FROM sys.dm_pdw_request_steps WHERE request_id = 'QID4302' ORDER BY step_index;

They are very different!
Further recommended reading: https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute

Pingback: The Shuffling Operator And Azure SQL DW – Curated SQL
Pingback: how does azure sql dw distribution work? - How to Code .NET
The Bills perdue pour les Dolphins au premier tour des playoffs.
LikeLike
Dwyane Wade et Chris Bosh jouent une grande ainsi que Luol Deng.
LikeLike
Excellent Article . Solved the slow running query using the ideas given in article
LikeLike