
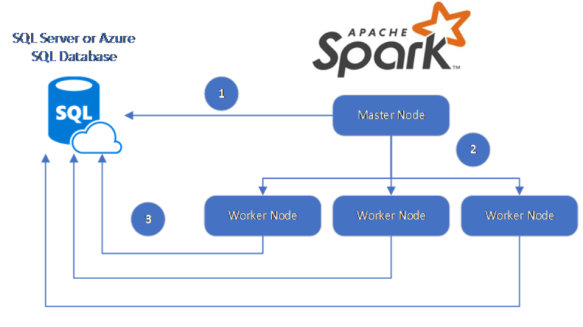
Recently I got to a stage where I leveraged Databricks to the best of my ability to join couple of CSV files together, play around some aggregations and then output it back to a different mount point ( based on Azure Storage) as a parquet file, I decided that I actually wanted to move this data into Azure SQL DB, which you may want to do one day.
As per the diagram.
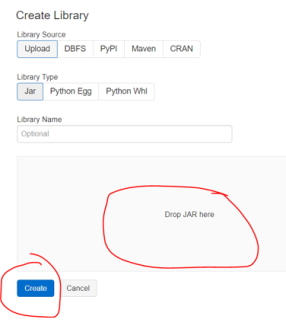
The documentation is there online, but I wanted to show you the screen shots to do this. Microsoft states that the spark connector should be used and the connector project uses maven. Ok great, what does that mean? Once you have your Databricks up and running on the main workspace menu you need to Import Library.

Switch to Maven and enter co-ordinate – com.microsoft.azure:azure-sqldb-spark:1.0.2.

Click create and your clusters will have access to it. As a side note if you ever need to install any JAR files, you can do that below:
Now you are ready for some notebook magic.

Once you have ran that, then below (just a random example) I moved the contents of my data frame to Azure SQL.
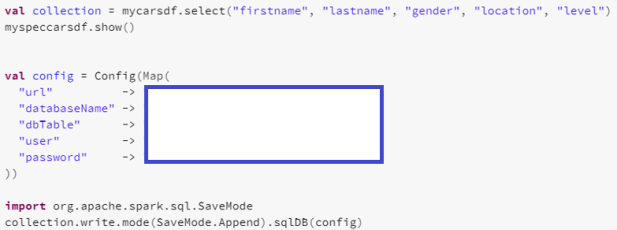
You can do the reverse if needed too.

Pingback: Feeding Databricks Output to Azure SQL Database – Curated SQL
How to load data from on-prem sql server to azure databricks table ?
LikeLike