Transaction log issues are one of the quietest ways a healthy database turns into an incident. A log file fills up, backups fall behind, and by the time anyone notices it is a 2am page rather than a five-minute fix. AgentDBA runs against SQL Server and explains, in plain language, what is wrong and what to do about it. Below is a real example of it catching one.
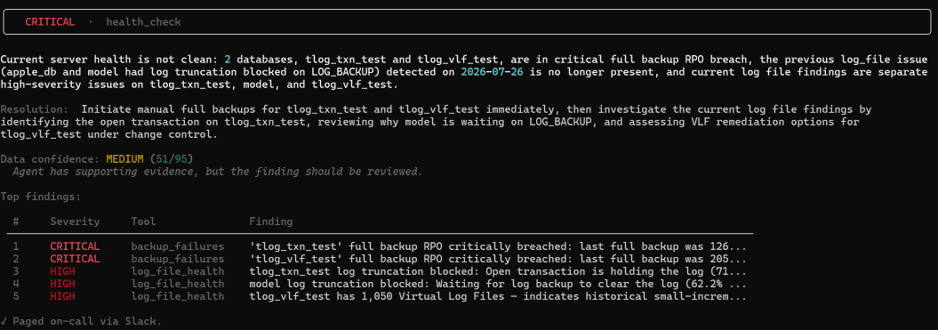
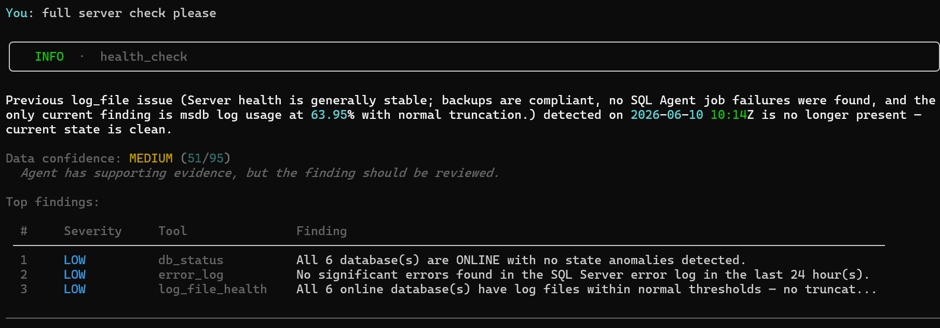
A routine full server check comes back CRITICAL. Two databases have blown through their backup RPO entirely (recovery point objective — how much data would be lost if a restore were needed right now), and three have separate high-severity transaction log problems. Instead of a wall of undifferentiated alerts, AgentDBA groups the findings, ranks them by severity, and attaches a confidence score (51/95, “has supporting evidence, but should be reviewed”) so the DBA knows exactly how much to trust the read before acting on it.
Following the evidence
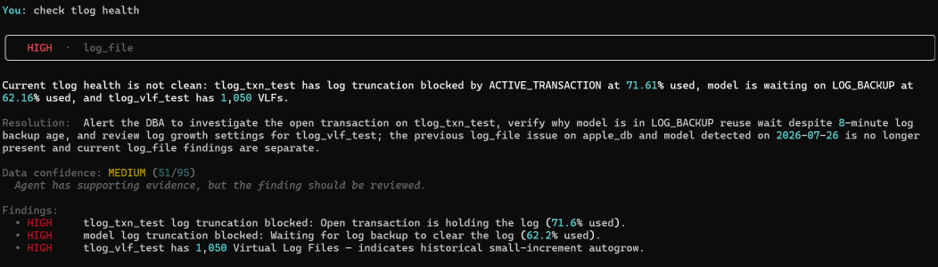
A quick follow-up question, “check tlog health,” drills straight into the detail: tlog_txn_test has an open transaction holding the log at 71.6% used, model is stuck waiting on a log backup, and tlog_vlf_test has 1,050 virtual log files — a telltale sign of small autogrow increments rather than a properly sized log. Each finding comes with a plain-English resolution, not just a symptom.
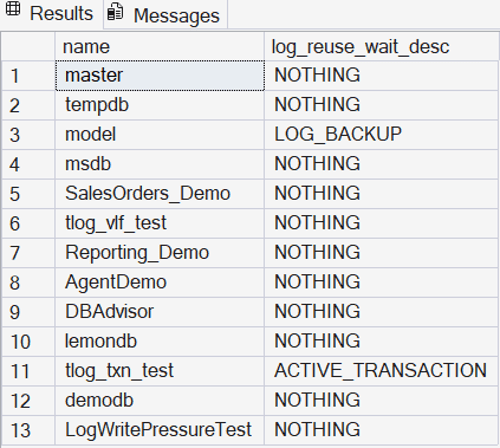
None of this is a guess. It is grounded in the same data a DBA would pull by hand — here, the log_reuse_wait_desc column straight from sys.databases, confirming the active transaction and the pending log backup wait.
Underlying evidence — verified directly against SQL Server, not inferred.
Connecting the dots
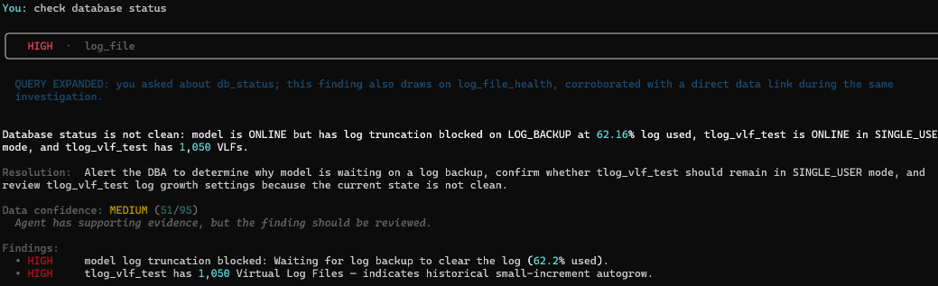
It also does this unprompted. Asking a separate question, “check database status,” pulls back the same underlying finding and says so explicitly: “you asked about db_status; this finding also draws on log_file_health, corroborated with a direct data link during the same investigation.” Rather than treating each question as a fresh, isolated lookup, it recognises the two are related and merges the evidence — so the DBA gets one coherent picture instead of having to cross reference two separate answers themselves.
Why this matters for DBAs
Time back: what is normally a 15–20 minute manual triage — checking sys.databases, log_reuse_wait_desc, VLF counts, and backup history separately — becomes a single question with a direct answer.
Trust, not blind faith: every finding ships with a confidence score and the underlying evidence, so the DBA can see why the agent believes what it believes rather than taking it on faith.
Connected context: findings link together across questions instead of resetting with every check, as shown above.
Until now, a CRITICAL finding did the right internal routing, but the last mile was a log line — useful for an audit trail, useless at 3am. v1.2.0 closes that gap: CRITICAL findings post straight to Slack, no human in the loop between detection and notification.
Sending a Slack message is a 15-line HTTP call within the app. The “thinking” part was everything downstream of that call — because for an alerting channel, a silent failure and a quiet night look the same from the outside.
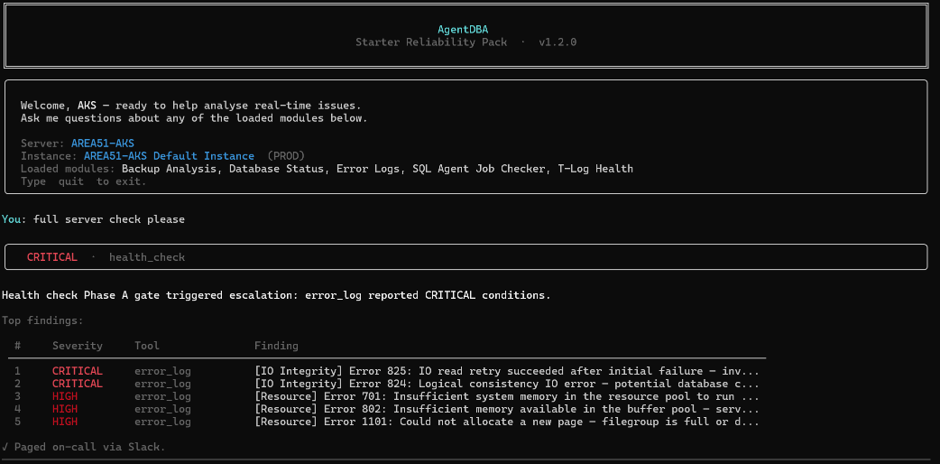
What does it look like? The main console will tell you it sent a Slack alert – Paged on-call via Slack message with a green tick – which it does.
Three outcomes, not two
The router used to have a binary result per channel: delivered or skipped. Fine when “skipped” meant “not configured.” Not fine once a send could genuinely fail mid-flight — timeout, bad webhook, Slack having a bad day. Collapsing “we chose not to send” and “we tried and it broke” into one bucket is exactly the ambiguity that lets an on-call engineer assume coverage that isn’t there.
So there’s a third state now: delivered, skipped (never attempted — not configured, or below the severity floor), and failed (attempted, didn’t work). A failed send never crashes the run, but it’s never silent either — the console tells the operator to notify on-call manually.
Don’t page the same fire twice
A single ongoing issue can trip the same finding repeatedly in a session — a database still degraded five minutes later isn’t new information (within the session). So repeat pages for the same category are suppressed after the first success, while a genuinely different category still gets through.
The detail that mattered: suppression is only earned by a confirmed delivery. A failed send does not count as “already paged” — otherwise one dropped message would silently blind the channel to every real incident of that category afterward.
What doesn’t go in the message
Server, severity, category, and a plain-language summary — nothing else. No query text, logins, or connection detail. A Slack channel is a wider trust surface than a DBA’s own terminal, so the message’s job is to say where to look, not to be the incident record.
Why this shape, and not more
The real design work here was deciding what “failure” honestly means for an alerting channel, and how little the message should say — the same two questions worth asking before wiring up anything whose whole job is to interrupt a human, some will probably want more context from slack, I chose to keep it minimal.
Every DBA has a box like this. Sitting untouched for months. Nobody’s proud of it, nobody’s fixed it, it’s just there — a handful of small compliance gaps that never made it to the top of anyone’s list.
I pointed AgentDBA at exactly that kind of instance. Then I made it worse on purpose.
Not every production incident is a database in RECOVERY_PENDING or a corrupted event (like the other post). Sometimes the server is just a mess. Jobs failing. Error log full of noise. Backups silently not running. No single catastrophic signal — just a slow accumulation of things going wrong that nobody has joined up yet. This is the other kind of scenario. No catastrophic signal to short-circuit on. AgentDBA reasons across all loaded modules and synthesises what it finds.
I connect AgentDBA to the server and type one thing. full server check
What comes back
The Agent sweeps across the loaded modules — backup analysis, database status, error logs, SQL Agent job checker, T-Log health — reasons across the findings and returns a single structured output.
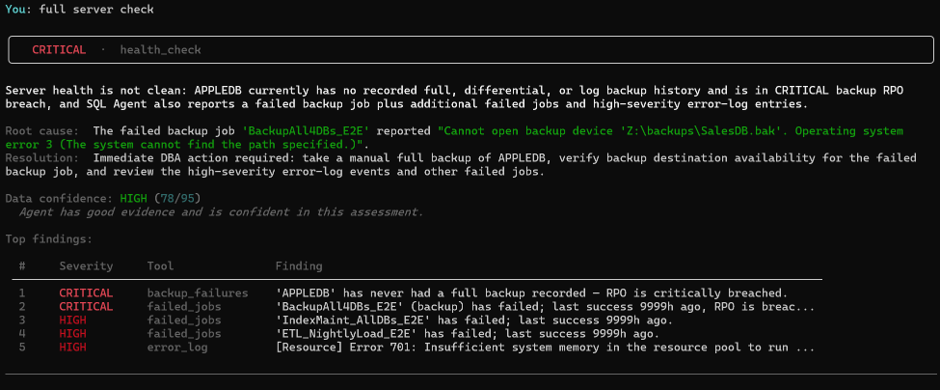
The banner is CRITICAL. The summary is precise: APPLEDB has never had a full backup recorded — the RPO is critically breached. The BackupAll4DBs_E2E job has failed, and the agent has already identified why: OS error 3 on Z:\backups\SalesDB.bak. The path doesn’t exist. Below that, two more failed jobs and high-severity error log entries ranked by severity.
Five findings. One output. Confidence scored at 78/95 — HIGH. The agent tells you it has good evidence and is confident in this assessment. It also tells you exactly what to do next.
This took seconds.
What shall I do?
I ask the obvious question.
The response is direct and specific. It does not say “investigate your backup jobs.” It says check BackupAll4DBs_E2E, verify the backup destination at Z:\backups\SalesDB.bak, and review error numbers 701, 802, 1101, 9002, and 17204 in the error log. It names the additional failed jobs that need separate review.
Every item on that list traces back to something a stored procedure returned. Nothing is inferred. Nothing is invented. If it is in the response, it came from the data.
The error log in isolation
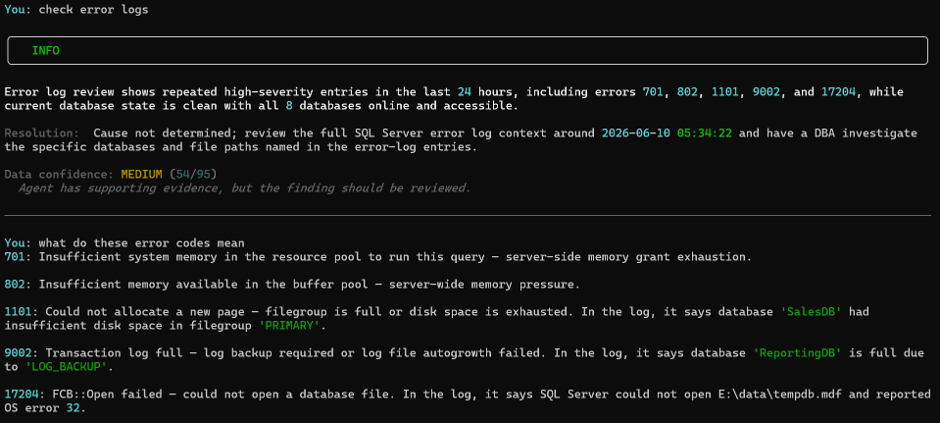
Before I drill into the jobs, here is something worth showing. I call the error log module directly.
Notice two things. The banner is INFO, not CRITICAL. Confidence is 54/95 — MEDIUM. The agent has supporting evidence but explicitly says the cause is not determined from the error log alone and the finding should be reviewed. It will not promote a finding to CRITICAL just because the error numbers are serious. Without corroborating evidence from other modules it does not have enough to be certain
The agent doesn’t return generic textbook definitions. It returns contextualised explanations tied to what it saw in the log. Error 1101 — filegroup full — it tells me that was SalesDB, filegroup PRIMARY. Error 9002 — transaction log full — it tells me that was ReportingDB, cause LOG_BACKUP. Error 17204 — file open failure — it tells me that was E:\data\tempdb.mdf, OS error 32.
What this demonstrates
A noisy server is harder to read than a catastrophic one. One critical failure with a clear signal is straightforward. Five overlapping findings across jobs, backups, error logs with varying severities and a buried root cause, is where manual diagnosis costs time.
AgentDBA swept five modules, ranked the findings, identified a specific root cause backed by evidence from the job error message, scored its own confidence, and told me exactly what to fix — in one invocation.
The root cause claim isn’t a suggestion. Its evidence bound. OS error 3 on a specific path is in the data. That’s why the confidence is 78/95 and not lower — the agent knows what it can and cannot prove, and it tells you both.
Please note AgentDBA is at beta stage – more information can be found at http://www.agentDBA.ai
AgentDBA is a self-hosted, CLI-based autonomous diagnostic reasoning engine for SQL Server. It is not a monitoring tool. It does not sit in the background polling metrics and firing alerts. You invoke it, it investigates, it reasons, and it tells you what it found and why.
The distinction matters. Monitoring tells you something happened. AgentDBA tells you what it means and what to look at next — grounded entirely in evidence it collected itself. No speculation. No plausible-sounding guesswork dressed up as a finding.
How it thinks
AgentDBA isn’t a script with an LLM bolted on. It reasons across multiple steps, remembers what it has seen before on your server, and decides for itself when it has enough evidence to conclude. Every action it takes is auditable — you can reconstruct exactly what it did and why without ever touching the LLM again. The LLM never receives raw SQL data. It receives structured, pre-processed findings. What it does with those findings is reasoning, not retrieval.
The non-negotiable: evidence first
The agent does not fill gaps with inference. Every finding must trace directly to data it collected. If the cause cannot be proven from what it holds, it says so — explicitly. That rule is not a prompt suggestion. It is enforced at code level.
When AgentDBA encounters a database integrity event or a critical error log condition, it doesn’t deliberate. It escalates immediately and ends the session. No reasoning loop. No sweep across other modules. Just the finding and a human on the hook.
When the critical class is clear, AgentDBA investigates the rest of the server. It selects which areas to examine, reasons across what it finds and concludes with severity and confidence — or with explicit uncertainty where evidence doesn’t support a conclusion. Every tool call, every decision, and every raw result is written to audit telemetry. The session is fully reconstructable from the database alone.
A clean server first
Before I introduce chaos, here is what AgentDBA looks like against a healthy server. I connect via Windows Auth, the LLM connects to Azure OpenAI GPT-5.4, and I run a full health check.
The server is clean. The only thing it surfaces is a historical finding: this server previously had a transaction log space warning on msdb, which I resolved. The agent knows this — it logged the episode, marked it resolved, and references it in context. It is not re-raising an issue that no longer exists.
Clean bill of health. Now let’s break things.
Scenario: The Critical Storm
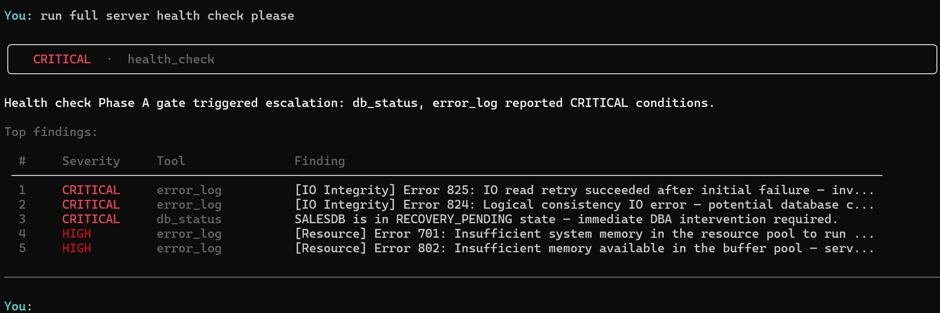
Many general failures but hidden deep within the group of issues are the dreaded Error 824 and Error 825 mixed with a RECOVERY_PENDING database means it cannot be accessed until someone intervenes.
These are not “look into it when you get a chance” events. These are the events that need looking at right away. I’ve staged exactly this on my VM server: a flood of errors (50+) in the SQL Server error log, 825 read retry events buried within them, and a database sitting in RECOVERY_PENDING. This is the kind of noise that hides the thing that matters.
I run the health check.
AgentDBA never reaches the LLM.
AgentDBA finds the CRITICAL conditions and short-circuits immediately. The RECOVERY_PENDING database is flagged. The 824/825 errors are flagged. The session ends. Escalation fires.
This is an explicit design decision. I do not want a reasoning loop when a database has a potential integrity event. I want to know immediately. Tell me. I’ll deal with it everything else can wait.
The escalation router has hooks for Slack and Teams — not wired up in this demo, but the architecture is there. A CRITICAL finding should be in your on-call channel before you’ve finished your coffee.
Fixing the critical issues
I work through the RECOVERY_PENDING database. I address the underlying cause and the critical checks now clear.
Missing Backups?
Once fixed, you call the agent again. With the critical class clear, AgentDBA now reasons across all other modules including failed jobs, backup compliance, log file health — and synthesises the finding.
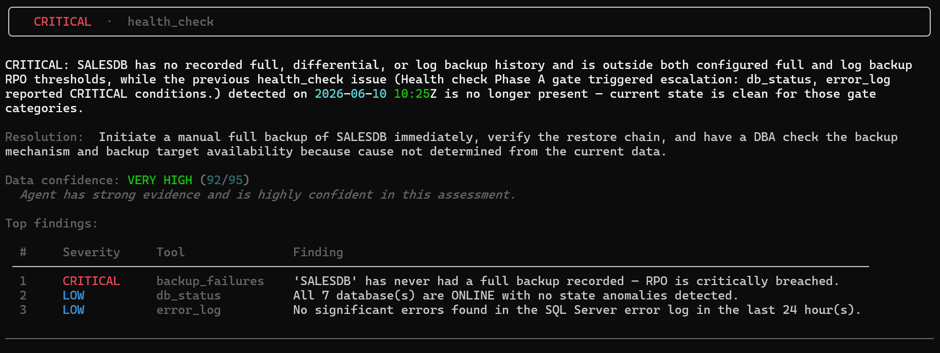
It comes back with a finding. Not catastrophic. But real. SALESDB has no backup recorded.
This hadn’t surfaced during the first run — not because the agent missed it, but because the critical-class check is intentionally scoped. It isn’t a full severity sweep. It is locked to a specific class of problem: database integrity and high severity errors that require immediate human intervention before anything else runs.
RECOVERY_PENDING and 824/825 errors are in that class – from my POV, these are non-negotiables, I used to have nightmares when confronted with potential corruption. A broken backup chain, even though important, is a different category of problem — serious yes but not corruption serious.
IMPORTANT – When you call a specific module directly, AgentDBA focuses there. When you call a full health check, it prioritises catastrophic conditions first before broader investigation.
Root cause — and when it stays null
It will not connect the missing backup to something like a job failure or make something up. It needs direct evidence otherwise this is fabrication. So, it will say root cause unknown or words to that effect.
That boundary is not a limitation. It is the feature. A diagnostic tool that invents causal chains sends you to fix the wrong thing.
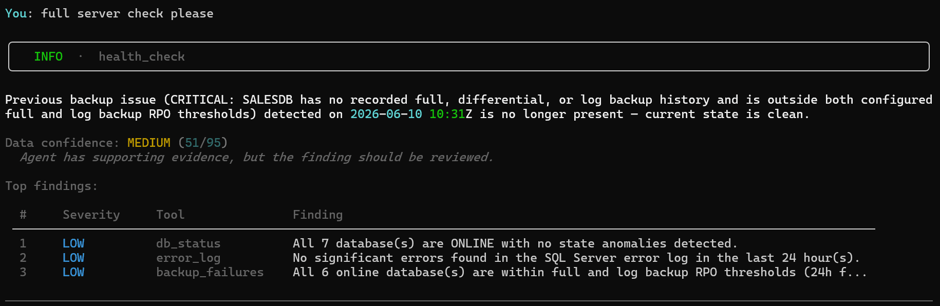
I fix the backup chain. I run again.
Everything is clean.
What this is
AgentDBA is not trying to replace your judgment. It is trying to make sure that when something is wrong, you are looking at the right thing and the right time within sixty seconds — not an hour later after manually correlating error logs, backup history, and job history across three SSMS windows.
The findings are evidence bound. The reasoning is auditable. And the longer it runs on your estate, the more context it carries. That is the point.
Please note AgentDBA is at beta stage – more information can be found at http://www.agentDBA.ai