
I have spent many long weekends getting stuck into Azure Databricks, plenty of time to understand the core functionality from mounting storage, streaming data, knowing the delta lake and how it fits into the bigger picture with tech like Event hubs, Azure SQL DW, Power BI etc.
So, I am going to show you how easy it is to create a cluster (that’s the end goal), you will appreciate the ease of deployment for huge amounts of infrastructure.
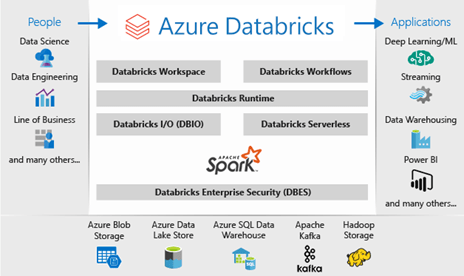
What is it? Taken from Databricks themselves, this says it all. (read more here https://databricks.com/blog/2017/11/15/a-technical-overview-of-azure-databricks.html)
Apache Spark + Databricks + Enterprise Cloud = Azure Databricks.
So, within the Azure portal – find Azure Databricks.
Click ADD – here I am keeping it simple with standard.

From a networking perspective you will probably need to deploy within a VNET.
Then hit the create button.

This creates the service where we will need to launch the workspace – where all the magic takes place.
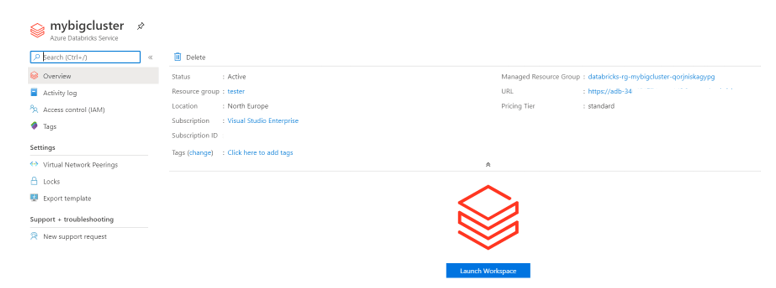
To create the cluster, you will see the cluster option on the left side (below).

As you can see below, I have one already in a terminated state (which I set to happen after 2 hours).
If you click into it you will the spec of the cluster.
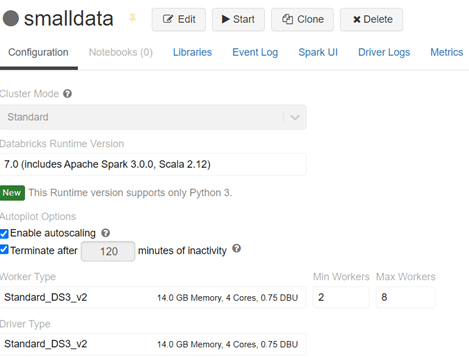
Cluster Mode – This is set to standard for me but you can opt for high concurrency too. There is quite a difference between the two types.

Runtime version – These are the core components that run on the cluster. There are many supported runtime versions when you create a cluster. You can also have runtimes for specific requirements, for example Runtime for genomics or machine learning too.
Autopilot options – I always use the” terminate after” option, this automatically terminates the cluster after a set idle time to save costs.
Worker and Driver Types –The driver node runs the Apache Spark master that coordinates with the Spark executors. The worker node is where all the distributed processing happens.
To get more details on these options – https://docs.databricks.com/clusters/configure.html I do not want to cut and paste.
To start interacting with the cluster you would create notebooks – which I will cover next blog post. Why is knowing about Databricks important? Well, it can truly become the central point for prepping and training your data within the Azure eco-system and interact with components such as event hubs for streaming data and obviously storage systems like the Data Lake get your data ( to and from). Yes we have Synapse Analytics nowadays where you can create spark pools, but for now, Databricks is my route forward.
