
On the theme of failover groups let’s do a quick recap on my environment. As shown below you can see the secondary database server called spacesql in West Europe.
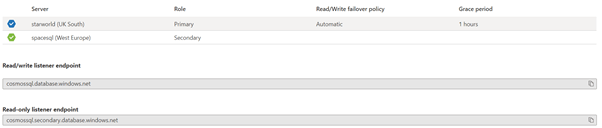
A common design approach is to leverage the read-only endpoint to facilitate read based queries.
Going back to my main post, knowing that you can fulfil read based queries via the dedicated endpoint I get asked if can you set the database to a higher tier (or lower)? You may want to do this if you know that you want to fulfil extremely high amounts of queries, for example you have a Power BI dashboard pointing to it. Do we need to consider the “mix” of tiers here? By this I mean, is there a combination of tiers that we cannot have once we have established a failover group?
The answer is yes. You cannot mix between some different tiers but you can have a higher compute size if you are within the same tier.
As you can see below, I can easily scale up the secondary database only. To do this, go to the secondary server and click the pricing tier.


As you can see, you can’t go lower to Basic but you can stay on Standard (Premium is supported). If going to the v-core model, study the below:

If you are on a Standard DTU model you can move across into General Purpose but not Hyperscale (makes sense) Or Business Critical – not sure why we can’t move to BC for the possible move because premium and business critical share the same architecture under the covers (I think it does anyway) so I am not sure why we can move into premium but not Business Critical, I am not complaining, end of the day gives you a better choice.
So, when designing this out for read capabilities make sure you do some research into whether or not the secondary tier you want is possible. For this scenario, I move my database into Premium Tier because I know I need the compute.

Pingback: Dew Drop – June 11, 2021 (#3463) – Morning Dew by Alvin Ashcraft