
If you have been following me for a while you will know that I really like the Fail over groups within Azure SQL DB and it is no different to when applying it to Managed Instances. If you want a rock-solid DR plan, this is the way forward.
Remember it’s an abstraction layer on top of the active geo-replication feature, before this we had to do a lot of manual one to one database setups but now this feature simplifies deployment and management of geo-replicated databases at scale. You can initiate failover manually or automatically if there is a massive failure (researching this topic this could mean things from memory leaks to wrong network cables cut during routine hardware decommissioning – you never know, it could happen so plan for it)
Lets look at setup. If you do not have a secondary MI already built, if you build one and go towards the end of the setup screens you will see the below.

You can flick the switch from No to Yes for using it has a secondary.

Click create

From a networking perspective there is a lot to configure for 2 Managed Instances that should be part of a failover group. For example, a requirement when participating in a failover group you WILL require Azure ExpressRoute, global VNet peering or two connected VPN gateways and you need to make sure you have no overlapping subnet ranges – please read this guide: https://docs.microsoft.com/en-us/azure/azure-sql/managed-instance/failover-group-add-instance-tutorial?tabs=azure-portal#create-a-secondary-managed-instance
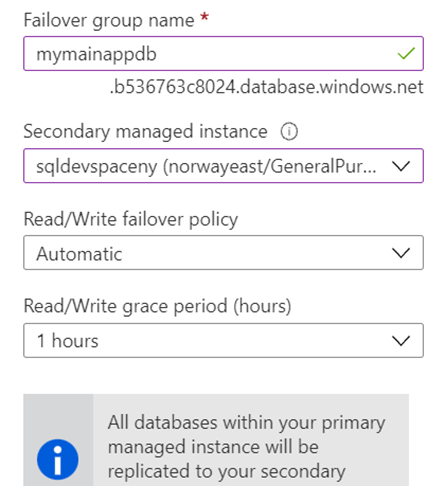
Once the deployment finishes (Which could take hours), go to the Failover section we are ready to finish the setup.
Add group.

Then enter the listener details and you will see the secondary is available for selection.
It has failed.. Some learnings coming up.
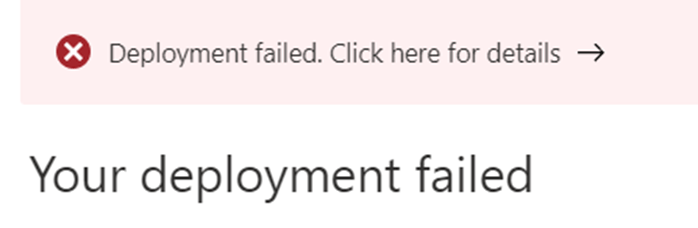
Why? Important lesson here, drill into the deployment details and check the message. I had a bad request.
"status": "Failed",
"error":
"code": "GeoDrInstanceSizeMismatch",
"message": "Primary managed instance and partner managed instance do not have the same storage size"
Ok so my primary has a max cap size of 64GB and the secondary is set to 256GB – should that really make a difference? I would think so if the values were reversed.
Ok – so I set both to 64GB and done.

Another learning I came across?
You cannot build a failover group if the secondary server is NOT empty!
status": "Failed",
"error": {
"code": "GeoDrSecondaryInstanceNotEmpty",
"message": "Failover group creation failed because geo-secondary managed instance is not empty."
}
Learning point? Storage sizes must be the same between primary and secondary server and the secondary must be empty before you build out the Fail over group.

Pingback: Managed Instance Failover Groups – Curated SQL