
Rarely do I say I love a feature across any technologies I have come across, in the snowflake world this is right up there.
I tend to find this feature useful when you have an important query that uses the equality sign = , the table is big, your definition of big may vary but in my example, I am talking around 89GB for one table in this example, the table is currently not clustered and the driving column within the predicate in the query has high cardinality.
I use Snowflake’s HLL – Hyper log log function to see the uniqueness of my columns.
SELECT
hll(CR_ORDER_NUMBER),
hll(CR_ITEM_SK),
hll(CR_RETURN_QUANTITY),
hll(CR_NET_LOSS)
from "SQLMI_DEV2_DB"."DATALOAD"."DATA_STAGING";

So I base this test on query like:
SELECT CR_NET_LOSS, CR_ORDER_NUMBER, CR_ITEM_SK FROM data_staging
WHERE CR_ORDER_NUMBER = 12553953913;
I will use a clone of the table to compare it to when search optimisation is on. I will make sure no caching in on which could affect the test.
I activate the feature via:
ALTER TABLE data_staging ADD SEARCH OPTIMIZATION;This takes time! If you run something like the below to confirm 100% completion. This is because there is a maintenance service that runs in the background responsible for creating and maintaining the search access path:
show tables like '%data_staging%';
I disable the use of cache and start a query against the clone which has no search enabled.
ALTER SESSION SET USE_CACHED_RESULT = FALSE;
SELECT CR_NET_LOSS, CR_ORDER_NUMBER, CR_ITEM_SK FROM data_staging_cloned
WHERE CR_ORDER_NUMBER = 12553953913;
37 seconds to return the row, spending most of the time during a table scan ( with a small warehouse).
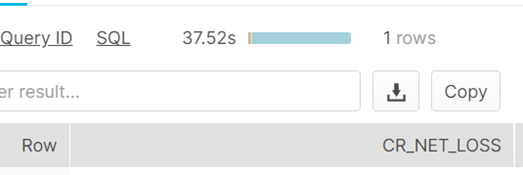
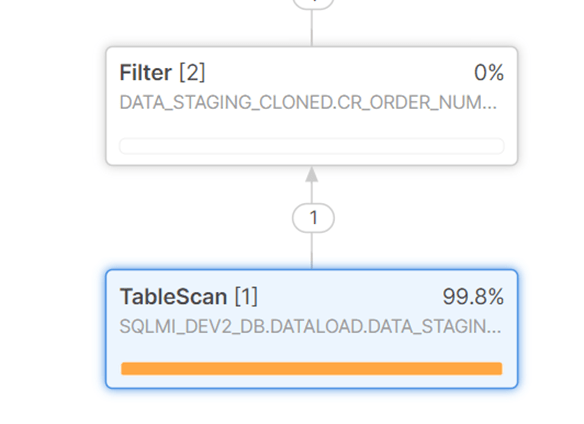
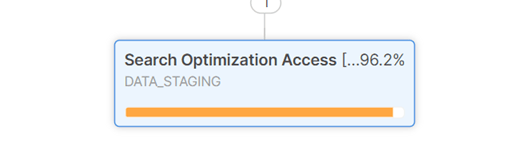
Compare it to the table with search enabled, we really need the query to return the row faster here. From 37 seconds to 1 second.


Pingback: Search Optimization in Snowflake – Curated SQL