
Cloning is a powerful feature within snowflake (also known as zero copy clone). You can obviously clone at the database or schema level but also tables too. It’s a snapshot of the object when the clone was taken. Its uses pointers to reference back to the original database but it will have its own micro-partitions when you start updating the clone so that is a cost you will need to consider; they are separate objects.
Let’s look at a basic example – I set the below context
USE DATABASE "SQLMI_DEV2_DB";
USE SCHEMA DATALOAD;
select * from customers;

Code for a table clone is:
CREATE OR REPLACE TABLE customer_clone
CLONE customers;
select * from customer_clone;

So what happens if I insert into the cloned table and compare to the original table?
insert into customer_clone values(10,'Mike','Tyson');
select * from customer_clone;

Go back to the original table:
select * from customers;
So this shows what I said at the start – they are different objects.
So what if I insert row into the original customer table ? will it show in the clone ? Obviously not because of the fact they are different objects now.
insert into customers values(100,'Frank','Smith');
select * from customer_clone;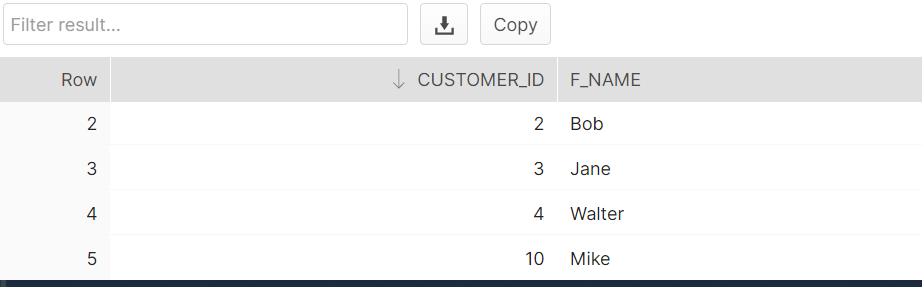
There is a lot to consider with cloning, I encourage more reading here – https://docs.snowflake.com/en/user-guide/object-clone.html
