This is an entry level post and a response to SQLEspresso’s blog challenge(http://sqlespresso.com/2017/01/10/ooops-was-that-was-me-blog-challenge) where we share mistakes from our “younger” days. My post takes me back 11 years and while it is nothing ground breaking I still want to convey what shrinking does to your database. Why? Well it was something that I USED to do. ( Again – I will reinforce the point it was a long time ago)
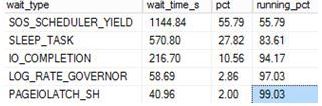
Well not only does it generate a lot of I/O, consumes CPU but it also affects your fragmentation levels in indexes which is what we will look at today.
These tables and indexes are based from Jonathan’s script found here: https://www.sqlskills.com/blogs/jonathan/enlarging-the-adventureworks-sample-databases/
So I issued the below TSQL where I would expect to see no fragmentation after the rebuild (Index level 0 being the leaf node). Yes the page count is low but it’s the concept I want to talk about.
ALTER INDEX PK_SalesOrderHeaderEnlarged_SalesOrderID ON Sales.SalesOrderHeaderEnlarged REBUILD
DECLARE @db_id SMALLINT;
DECLARE @object_id INT;
SET @db_id = DB_ID(N'AdventureWorks1997');
SET @object_id = OBJECT_ID(N'Sales.SalesOrderHeaderEnlarged');
IF @db_id IS NULL
BEGIN;
PRINT N'Invalid database';
END;
ELSE IF @object_id IS NULL
BEGIN;
PRINT N'Invalid object';
END;
ELSE
BEGIN;
SELECT * FROM sys.dm_db_index_physical_stats(@db_id, @object_id, NULL, NULL , 'detailed');
END;
GO

Now let’s SHRINK. You can actually do this via SQL Server Management Studio.
DBCC SHRINKDATABASE(N'AdventureWorks1997' )
GO
DECLARE @db_id SMALLINT;
DECLARE @object_id INT;
SET @db_id = DB_ID(N'AdventureWorks1997');
SET @object_id = OBJECT_ID(N'Sales.SalesOrderHeaderEnlarged');
IF @db_id IS NULL
BEGIN;
PRINT N'Invalid database';
END;
ELSE IF @object_id IS NULL
BEGIN;
PRINT N'Invalid object';
END;
ELSE
BEGIN;
SELECT * FROM sys.dm_db_index_physical_stats(@db_id, @object_id, NULL, NULL , 'detailed');
END;
GO
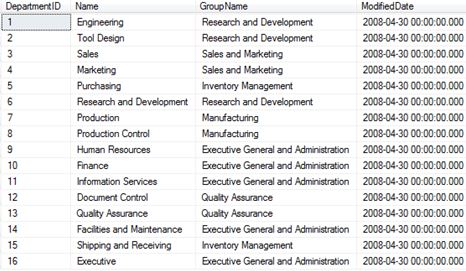
99.85% avg_fragmentation, in essence the order has been reversed.
 Ok, for a one-of activity I don’t mind you could just sort out the fragmentation afterwards, but to do it as part of a maintenance routine, not the best option out there. SHAME ON ME!
Ok, for a one-of activity I don’t mind you could just sort out the fragmentation afterwards, but to do it as part of a maintenance routine, not the best option out there. SHAME ON ME!