I have a need to encrypt a column within my SQL Database (Azure). I decided to use Always Encrypted. This feature essentially uses a column encryption key that is used to encrypt data in an encrypted column and a column master key that encrypts one or more column encryption keys.
It is paramout that you install an Always Encrypted-enabled driver on the client as the driver encrypts the data in sensitive columns before passing the data to the database engine.
Your application connection string will be something similar to:
string connectionString = "Data Source=yourserver; Initial Catalog=mydb; Integrated Security=true; Column Encryption Setting=enabled"; SqlConnection connection = new SqlConnection(connectionString);
Doing this is important because if you have the setting disabled and you have a query with parameters targeting an encrypted column it will fail. The following table from Books on Line summaries this (last column).

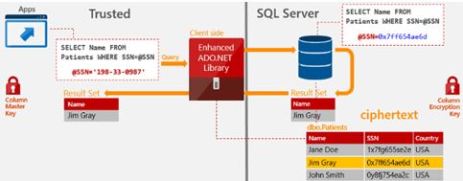
There is a lot to digest for this feature it’s not just the database you need to consider; a picture speaks a thousand words so have a look how everything sits together.
Setup via the wizard
Navigate to your column of interest and click the Encrypt Columns option
The wizard arrives
Next is column selection – This will be my salary column (ok it may not be a great example but it’s the idea I want to convey)
Always Encrypted uses AEAD_AES_256_CBC_HMAC_SHA_256 algorithm. There are 2 variations available, this being deterministic and randomized.
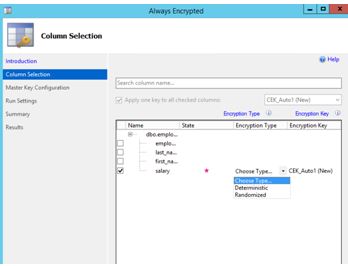
Deterministic – This is the weaker option of the 2. It uses a method which always generates the same encrypted value for any given plain text value. It allows for grouping, filtering by equality, and joining tables based on encrypted values. Be aware that Deterministic encryption must use a column collation with a binary2 sort order for character columns.
Randomised – Less predictable than the above, it does not allow for grouping and filtering on the encrypted column.
You have to make a choice here; both options have pros and cons. If you know that you need to do grouping, indexing or joins on your encrypted column then you don’t really have a choice and will have to use deterministic.
For my example I am going with randomised. If you try and group/filter on a column with randomised you will get:
Msg 33299, Level 16, State 2, Line 8 – Encryption scheme mismatch for columns/variables ‘salary’. The encryption scheme for the columns/variables is (encryption_type = ‘RANDOMIZED’, encryption_algorithm_name = ‘AEAD_AES_256_CBC_HMAC_SHA_256’, column_encryption_key_name = ‘CEK_Auto1’, column_encryption_key_database_name = yourdb) and the expression near line ‘8’ expects it to be (encryption_type = ‘DETERMINISTIC’) (or weaker).
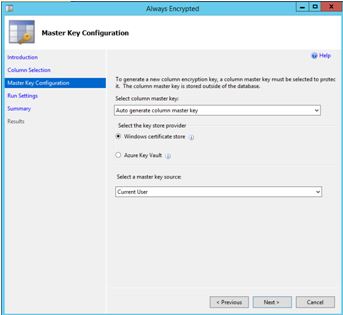
Next is master key configuration. Ideally I would love to setup the Azure Key Vault provider but I think that would make a great blog post (one day), so here I opted for Windows certificate store.
Save the PowerShell script if you desire.
Issue your query now:
![]()
As mentioned before this is only 1 piece of the puzzle, you need to make application changes to handle this encryption. I suggest reading through https://msdn.microsoft.com/en-us/library/mt757097.aspx as this shows you how to build your queries (the documentation is in .NET) the last thing you want is to see something like –
System.Data.SqlClient.SqlException (0x80131904): Operand type clash: varchar is incompatible with varchar(8000) encrypted with (encryption_type = ‘DETERMINISTIC’, encryption_algorithm_name = ‘AEAD_AES_256_CBC_HMAC_SHA_256’, column_encryption_key_name = ‘CEK_Auto1’, column_encryption_key_database_name = ‘mydb’) collation_name = ‘SQL_Latin1_General_CP1_CI_AS’
I also suggest reading the Feature detail section found here https://msdn.microsoft.com/en-us/library/mt163865.aspx