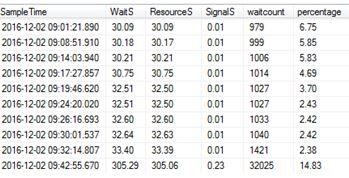
This week’s TSQL Tuesday is being held by the mighty Kenneth Fisher – Backup and Recovery- see this link, how can I not get involved with this one?

I have been blogging for about a year now and have covered most of Kenneth’s bullet points – except Internals and SSAS based stuff, so I decided to do something different but still about backups. This post is all about the importance of backing up certain objects when you are using TDE – Transparent Data Encryption.
To understand TDE see my older post – https://blobeater.blog/2016/11/22/playing-with-tde/
So I have enabled TDE and I have a Full backup – lets restore it to a different server.
USE [master] RESTORE DATABASE [DWHDB] FROM DISK = N'C:\temp\dwh.bak' WITH FILE = 1, STATS = 5 GO
Cannot find server certificate with thumbprint ‘0xC0367AC8E9AE54538C17ACB0F63070D6FF21316A’.
Msg 3013, Level 16, State 1, Line 2
RESTORE DATABASE is terminating abnormally.
The dreaded cannot find server certificate with thumbprint message. Why is this happening?
Well if you read my post on TDE ( or anybody else’s) you would have noticed the following message:
Warning: The certificate used for encrypting the database encryption key has not been backed up. You should immediately back up the certificate and the private key associated with the certificate. If the certificate ever becomes unavailable or if you must restore or attach the database on another server, you must have backups of both the certificate and the private key or you will not be able to open the database.
So the point is – back them up
USE master GO BACKUP CERTIFICATE MyServerCert TO FILE = 'c:\data\MyServerCert.cer' WITH PRIVATE KEY (FILE = 'c:\data\certificate_MyServerCert.pvk', ENCRYPTION BY PASSWORD = 'xxxxxxxx')
Then on the restoring server you will need to issue the following (assuming you have a database master key too)
CREATE CERTIFICATE MyServerCert FROM FILE = 'c:\temp\MyServerCert.cer' WITH PRIVATE KEY (FILE = 'c:\temp\certificate_MyServerCert.pvk', DECRYPTION BY PASSWORD = 'xxxxxxxx'); GO USE [master] RESTORE DATABASE [DWHDB] FROM DISK = N'C:\temp\dwh.bak' WITH FILE = 1, STATS = 5 GO
RESTORE DATABASE successfully processed 13002 pages in 0.444 seconds (228.770 MB/sec) – the restore works a charm.