I know there are people out there that will be going from older versions of SQL to SQL Server 2016, yes it makes sense it is a great product with a lot of new features such as Query Store, Stretch DB to name but a few.
However don’t forget about the features that were available in 2014 that are naturally available in 2016, such as the ability to control blocking behaviors when rebuilding indexes.
Classically when you want to use the ONLINE mode of rebuilding indexes the code would look like:
ALTER INDEX [MCD] ON [dbo].[mcdaol] REBUILD WITH(ONLINE = ON)
Looking into the locking you will see that ONLINE operation uses (Sch-M) on the corresponding table as part of the process (actually takes Shared Table Lock (S) at the beginning of the operation, and a Schema Modification Lock (Sch-M at the end)).
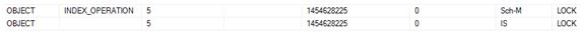
So to be granted a SCH-M lock you can’t have any conflicting locks, so what happens when / if you have a process that is updating the table and you want to use the ONLINE rebuild? Yes you will be blocked. With 2014 onwards we can control what happens if we get into this situation and for this post I am going to abort the other query causing me to wait.
Let’s see what happens.
I have 1 window running an update such as:
— Open Trans
BEGIN TRAN UPDATE [dbo].[p_dinner] SET og_status = 1 WHERE og_status = 10
In a different window I am running the Index rebuild:
ALTER INDEX [p_dinner_idx] ON [dbo].[p_dinner] REBUILD WITH(ONLINE = ON)
Naturally this will be blocked.

So now we can control what happens here, for this example I want to kill the connection holding the locks that are conflicting with my rebuild i.e. the update (just an example).
So I run:
ALTER INDEX [p_dinner_idx] ON [dbo].[p_dinner] REBUILD
WITH
(
ONLINE = ON
(
WAIT_AT_LOW_PRIORITY
(
MAX_DURATION = 1,
ABORT_AFTER_WAIT = BLOCKERS
)
)
)
GO
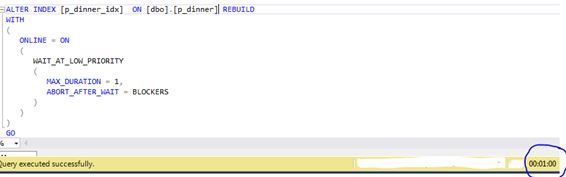
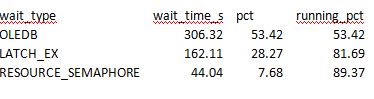
From the above image you can see after 1 minute (MAX_DURATION) the query successfully executes because it killed the connection causing the blocking, which is done via the ABORT_AFTER_WAIT = Blockers clause.